handel_file = 'health_handel.csv' #分词好要保存的数据文件路径 #读取数据 data=pd.read_excel('health.xlsx') print(data.head(10)) stopwords = nc.stopwords.words('english') #停用词 tokenizer=tk....
”健康 分词 词性标注 领域“ 的搜索结果
HMM模型+维特比算法实现分词词性标注.py
使用keras实现的基于Bi-LSTM CRF的中文分词 词性标注
将需要分词进行词性标注的句子存放在corpus文本文件(自建)中,最好是每句话存为一行。注:corpus文件需放在代码所在文件夹里。运行代码,自动生成一个outcome文本文件,分词词性标注结果就在此文本里。
Java 实现的自然语言处理 中文分词 词性标注 命名实体识别 依存句法分析 关键词提取 自动摘要 短语提取 拼音 简繁转换。.zip,自然语言处理 中文分词 词性标注 命名实体识别 依存句法分析 新词发现 关键词短语提取 ...
Sequence labeling base on universal transformer (Transformer encoder) and CRF; 基于Universal Transformer CRF 的中文分词和词性标注
目录提供的功能有:中文分词词性标注命名实体识别知识图谱关系抽取关键词提取文字摘要新词发现情感分析文本聚类等等。。。。安装方式点安装pip install -U jiagu如果比较慢,可以使用清华的pip源: pip install -U ...
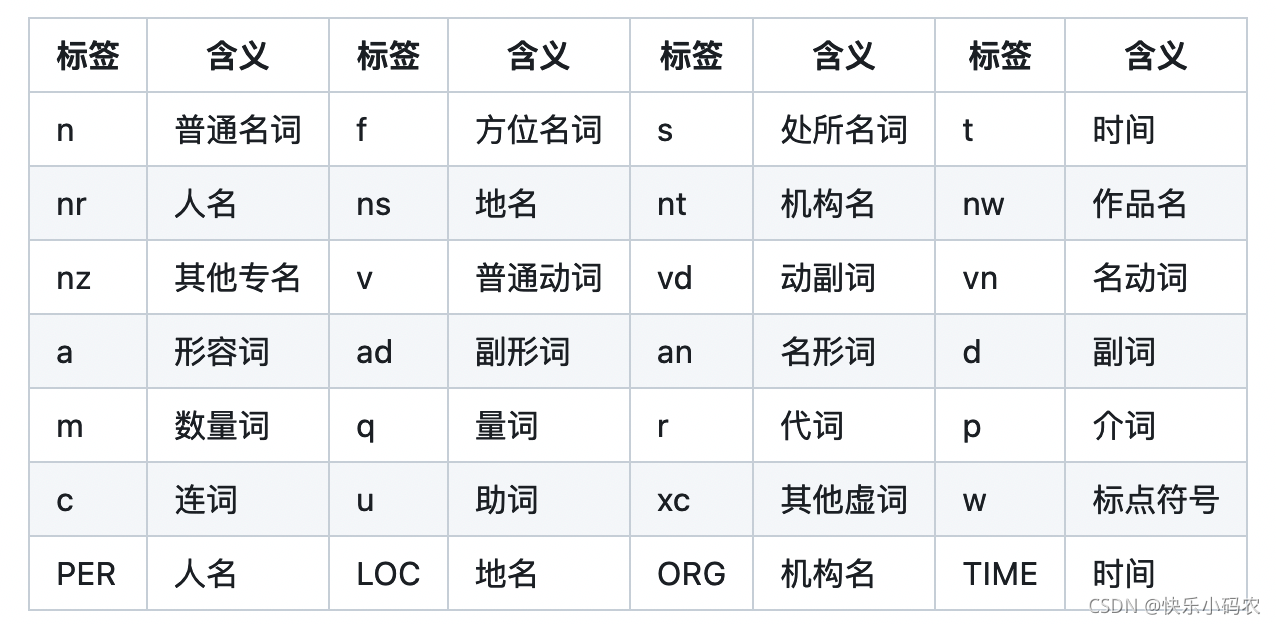
词性标注如图,在 DAG分词时所用的 dict 里面含有词汇、词频和词性三个信息。所以,最简单的情况下,只需要在分词时查询 dict 记录下每个词的词性即可。对于 dict 中没有给出 pos 信息,或者采用 Viterbi 算法对 OOV...
将提供中文分词、词性标注、命名实体识别、情感分析、知识图谱关系抽取、关键词抽取、文本摘要、新词发现、情感分析、文本聚类等常用自然语言处理功能。参考了各大工具优缺点制作,将Jiagu回馈给大家。 目录 安装...
词性标注 句法分析 文本向量化 情感分析 基于机器学习的 NLP 算法 +源代码+文档说明 2、代码特点:内含运行结果,不会运行可私信,参数化编程、参数可方便更改、代码编程思路清晰、注释明细,都经过测试运行成功,...
支持中文分词(N-最短路分词、CRF分词、索引分词、用户自定义词典、词性标注),命名实体识别(中国人名、音译人名、日本人名、地名、实体机构名识别),关键词提取,自动摘要,短语提取,拼音转换,简繁转换,文本...
中文分词 词性标注 命名实体识别 依存句法分析 成分句法分析 语义依存分析 语义角色标注 指代消解 风格转换 语义相似度 新词发现 关键词短语提取 自动摘要 文本分类聚类 拼音简繁转换 自然语言处理.zip
基于Pytorch+BERT+CRF的NLP序列标注模型,目前包括分词,词性标注,命名实体识别等.zip 基于Pytorch+BERT+CRF的NLP序列标注模型,目前包括分词,词性标注,命名实体识别等.zip基于Pytorch+BERT+CRF的NLP序列标注...
C# 中文分词 词性标注
import jieba import jieba.analyse import jieba.posseg def dosegment_all(sentence... 带词性标注,对句子进行分词,不排除停词等 :param sentence:输入字符 :return: ''' sentence_seged = jieba.posseg.cu...
词性标注 (速度快) 、(精度高) 命名实体识别 基于HMM角色标注的命名实体识别(速度快) 、、、、 基于线性模型的命名实体识别(精度高) 、 关键词提取 自动摘要 短语提取 多音字、声母、韵母、声调 简繁分歧词...
人工智能-项目实践-深度学习
工具介绍LAC全称中文的词法分析,是百度自然语言处理部研发的一种联合的词法分析工具,实现中文分词,词性标注,专名识别等功能。该工具具有以下特点和优势:效果好:通过深度学习模型联合学习分词,词性标注,专名...
pyhanlp的内容很多,这篇文章先介绍分词和词性标注这一部分。顺便写一个简介。简介pyhanlp是HanLP的Python接口。因此后续所有关于pyhanlp的文章中也会写成HanLP。HanLP是完全用Java自实现的自然语言处理工具包。特点...
基于Python的中文分词词性标注词频统计的实现 今天是2018年10月22号,小亮继续着自己深度学习与自然语言处理的打怪升级之路。今天给大家介绍一下最近接的小项目,基于Python的中文分词词性标注词频统计的实现,在...
基于隐马尔科夫模型的序列标注(python源码+项目说明)(用于中文分词、词性标注、命名实体识别等).zip 基于隐马尔科夫模型的序列标注(python源码+项目说明)(用于中文分词、词性标注、命名实体识别等).zip 基于...
中文分词词性标注命名实体识别依存句法分析语义依存分析新词发现 的golang界面 在线轻量级RESTful API 仅数KB,适合敏捷开发,移动APP等场景。服务器算力有限,匿名用户重新替代 使用方式 安装 go get -u github....
Seg_Pos 中文分词与词性标注工具的性能比较 中文分词和词性标注的模型: (, , , )中文分词和词性标注工具性能对比 模型下载地址:链接: ://pan.baidu.com/s/1sgwBEOX1sEZC9bBVYVPTEw密码:fgky
文章目录一、Python第三方库jieba(中文分词、词性标注)特点二、jieba中文分词的安装关键词抽取基于TF-IDF算法TF-IDF原理介绍基于TextRank算法的关键词抽取textRank算法原理介绍总结 一、Python第三方库jieba...
借助世界上最大的多语种语料库,HanLP2.1支持包括简繁中英日俄法德在内的104种语言上的10种联合任务:分词(粗分、细分2个标准,强制、合并、校正3种)、词性标注(PKU、863、CTB、UD四套词性规范)、命名实体识别...
分词及词性标注在英文中,计算机能够利用词语之间的空格来辨别每一个单词词语,但是由连续中文文本组成的汉语序列,因为其词和词之间没有任何标识来进行划分,所以计算机无法方便的直接进行分词处理。然而计算机在对...
jieba分词的基本用法和词性标注 一、jieba 分词基本概述 它号称“做最好的Python中文分词组件”的jieba分词是python语言的一个中文分词包。 它有如下三种模式: 精确模式,试图将句子最精确地切开,适合文本...
pyhanlp:HanLP1.x的Python接口 的Python接口,支持自动下载和升级 ,兼容py2,py3。...使用命令hanlp segment进入交互分词模式,输入一个句子并回车, 会输出分词结果: $ hanlp segment 商品和服务
推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地